
Executive Summary: In a 6:30-minute live streaming test with challenging German technical content, AWS Transcribe achieved the lowest Word Error Rate (WER) and demonstrated the most stable latency. GCP's Chirp2 came in close second – with slight improvement using Phrase Sets. The GCP Long model proved unsuitable for live scenarios with a 40-second limit (many deletions/missing responses).
Key Findings
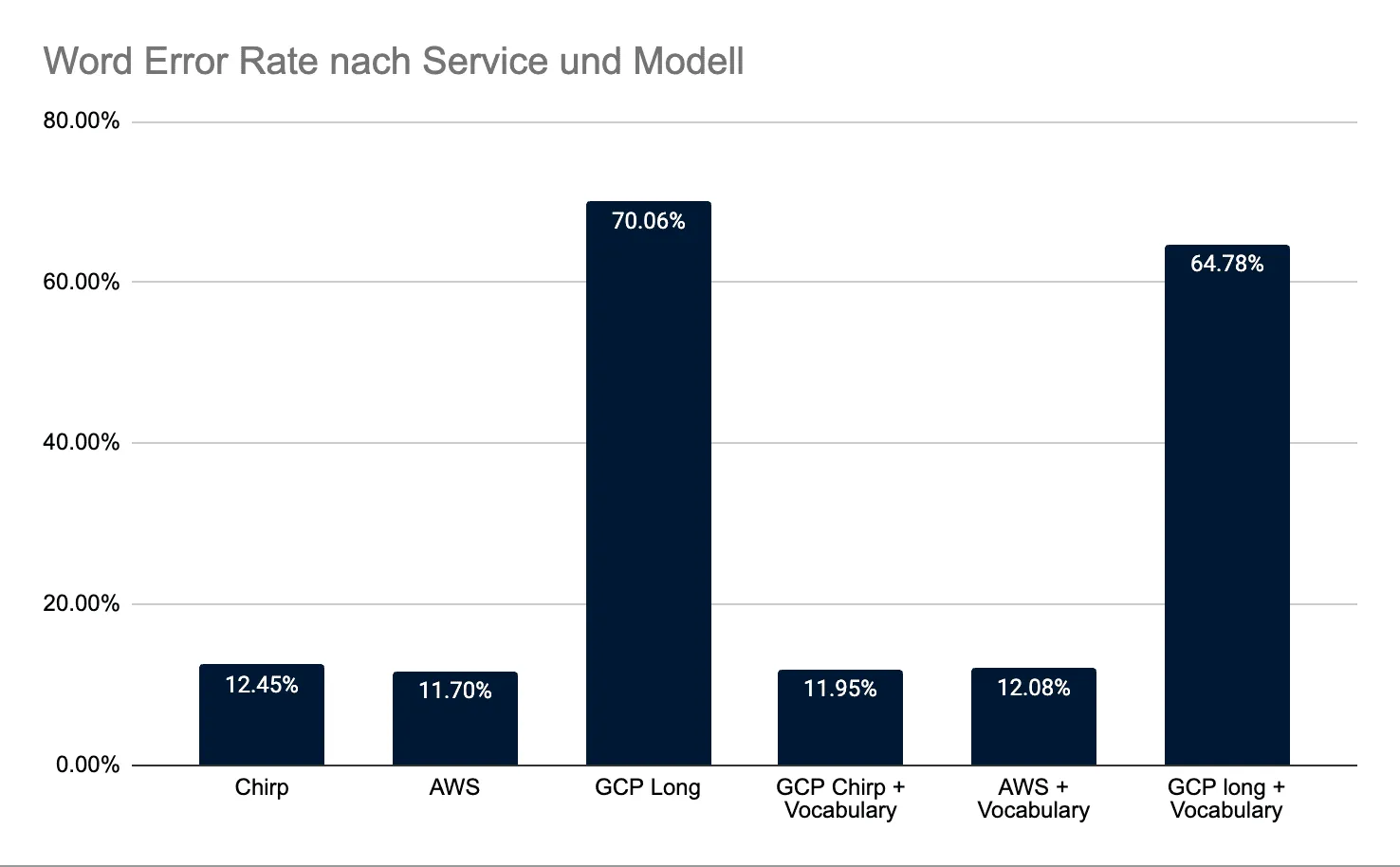
- For German live transcription with strict latency constraints, AWS Transcribe was the most reliable (WER 11.70%).
- GCP Chirp2 benefited moderately from Phrase Sets (WER 12.45% → 11.95%).
- GCP Long delivered massive deletions in streaming setup due to high/inconsistent latency (WER 64–70%) and is unsuitable for live use.
Why You Should Care
If you rely on real-time subtitles for webinars, live events, or support calls, accuracy alone isn't enough – reliability within your time window matters. This case study shows which services perform in live operations and how you can improve results with Phrase Sets/vocabulary.
Setup Overview
- Language: German
- Input: approx. 6:30 minutes of continuous speech (technical jargon, numbers, proper names, dialects, anglicisms)
- Services:
- AWS Transcribe
- GCP Cloud Speech-to-Text: Chirp2
- GCP Cloud Speech-to-Text: Long
- Each with and without vocabulary/Phrase Set (6 test runs)
- Live streaming scenario: max. 40 seconds latency; later results were discarded
- WER calculation: (Substitutions + Deletions + Insertions) / Total Words; punctuation normalized
Important Constraint Results arriving later than 40 seconds were considered "discarded." This penalizes models with slow/inconsistent finalization behavior – exactly what occurred with the GCP Long model.
The Test Transcript (Requirements)
The presentation "The Future of AI and Its Societal Impact" deliberately covers transcription challenges:
- Compound words (e.g., Donaudampfschifffahrtsgesellschaftskapitän)
- Numbers/statistics (monetary amounts, percentages, years, phone numbers, postal codes)
- Technical terminology (medicine, physics, biochemistry, IT)
- Abbreviations/acronyms (NATO, UNESCO, GDP, DAX, ECB, ROI, DNA, RNA, IoT)
- Proper names/institutions (e.g., UKE, Volkswagen AG)
- Dialectal expressions (Swabian, Bavarian, Northern German)
- Time/date formats and contact information
The goal was to simulate a realistic, "hard" live scenario.
Results
| System | Word Error Rate | Accuracy | Errors | Correct | Subs | Del | Ins |
|---|---|---|---|---|---|---|---|
| Chirp | 12.45 % | 87.55% | 99 | 717 | 59 | 19 | 21 |
| Chirp + vocabulary | 11.95 % | 88.05% | 95 | 715 | 54 | 26 | 15 |
| AWS | 11.70 % | 88.30% | 93 | 712 | 70 | 13 | 10 |
| AWS + vocabulary | 12.08 % | 87.92% | 96 | 711 | 71 | 13 | 12 |
| GCP Long | 70.06 % | 29.94% | 557 | 250 | 48 | 497 | 12 |
| GCP long + vocabulary | 64.78 % | 35.22% | 515 | 303 | 55 | 437 | 23 |
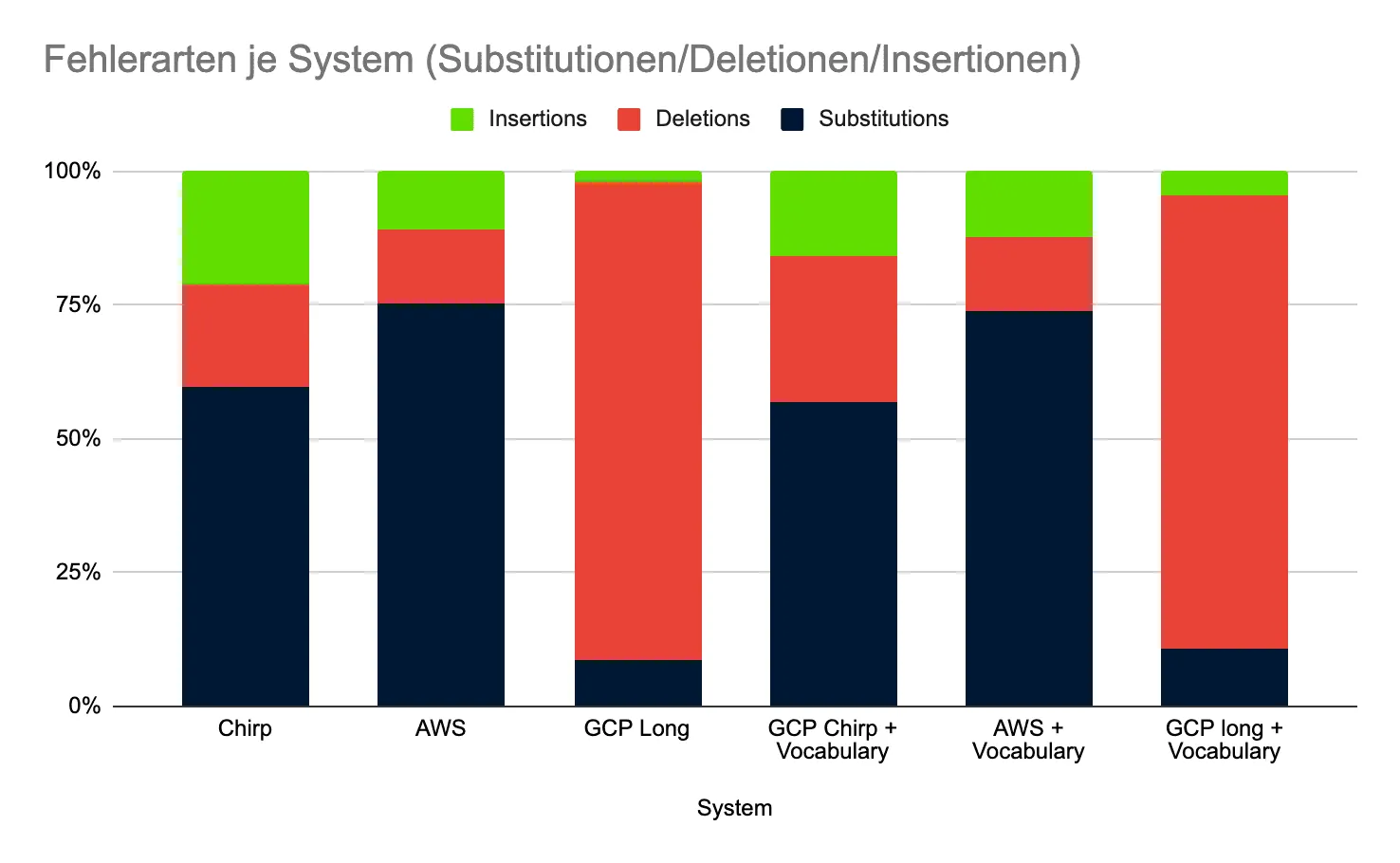
Subs: Substituted words, Del: Deleted words, Ins: Inserted words
Interpretation
- AWS Transcribe: lowest WER (11.70%), with few deletions → reliable within the live window.
- GCP Chirp2: similarly good, with slight improvement using Phrase Sets. Slightly more deletions than AWS, but fewer insertions/sometimes fewer substitutions.
- GCP Long: very high deletions (497 and 437 respectively) → strongly indicating that finalizations often didn't arrive within the 40-second window. Marginally better with Phrase Set, but still problematic for live use.
Latency Matters Latency with GCP was sometimes highly variable; AWS ran more stably. Without consistent finalizations, WER climbs – not because the acoustic modeling is inherently "bad," but simply because results arrive too late.
What Do Phrase Sets/Vocabulary Mean in Practice?
- GCP Chirp2 benefited slightly from Phrase Sets (−0.5 percentage points WER), especially for proper names/terminology.
- AWS showed no advantage with Phrase Sets here (even marginally worse). The cause may be over-biasing leading to substitutions/insertions.
- GCP Long benefits somewhat content-wise but remains problematic in live mode due to latency.
Practical Tip
- Use Phrase Sets selectively and specifically (proper names, product terms, acronyms).
- Test weightings; overly aggressive boosts can increase misallocations.
- Update Phrase Sets dynamically before events (e.g., speaker names, agenda, company names).
Recommendations for Your Live Setup
- Choose the model based on mode, not just "accuracy on paper"
- Live (strict latency): AWS Transcribe or GCP Chirp2 (with cautious Phrase Set) are practical.
- Offline/Batch: GCP Long may be interesting – but not for tight real-time windows.
- Plan for latency uncertainties
- Set timeouts, but log late arrivals separately for post-event analysis.
- Use buffering/segmentation (e.g., 10–15-second chunks) to promote more stable finalizations.
- Optimize acoustics and normalization
- Clean, consistent audio levels; avoid room echo.
- Post-processing: correct number/date/phone formatting with RegEx/heuristics.
- Augment speech recognition with domain knowledge (e.g., abbreviation mappers).
- Measure more than just WER
- Separate error types: High deletion → latency/stability problem, high substitution → acoustics/language model or over-biasing, high insertion → overly aggressive hypotheses.
- Monitor "Time-to-Final" and revision frequency of interim hypotheses.
Study Limitations
- Single presentation, though content-wise broad and challenging.
- Six sequential runs rather than parallel; possible run-to-run variance.
- No quantitative latency metrics collected (only qualitative observation).
- Vendor configurations not tuned to maximum (deliberately practical).
How to Get More from Your Own Tests
- Use multiple speakers, environments, and lengths.
- Log Time-to-Final, stability of interim hypotheses, jitter.
- Test different Phrase Set weightings and channel/sample rates.
Conclusion
For German live transcription with tight latency windows, AWS Transcribe was the most robust choice in this test, closely followed by GCP Chirp2 (with slight boost from Phrase Sets). The GCP Long model delivered too many deletions in streaming operation, presumably due to delayed finalizations.
If you're captioning a live event today, start with AWS or GCP Chirp2, keep Phrase Sets lean and measurable, and consistently monitor latency and error types. This will give you more reliable subtitles – and a better experience for your audience.


