
Kurzfassung: In einem 6:30‑Minuten Live-Streaming-Test mit anspruchsvollem deutschen Fachvortrag erzielte AWS Transcribe die niedrigste Word Error Rate (WER) und zeigte die stabilste Latenz. GCPs Chirp2 lag knapp dahinter – mit Phrase Set leicht verbessert. Das GCP‑Long‑Modell erwies sich im Live‑Szenario mit 40‑Sekunden‑Grenze als ungeeignet (viele Deletionen/ausbleibende Rückmeldungen).
Kernaussagen
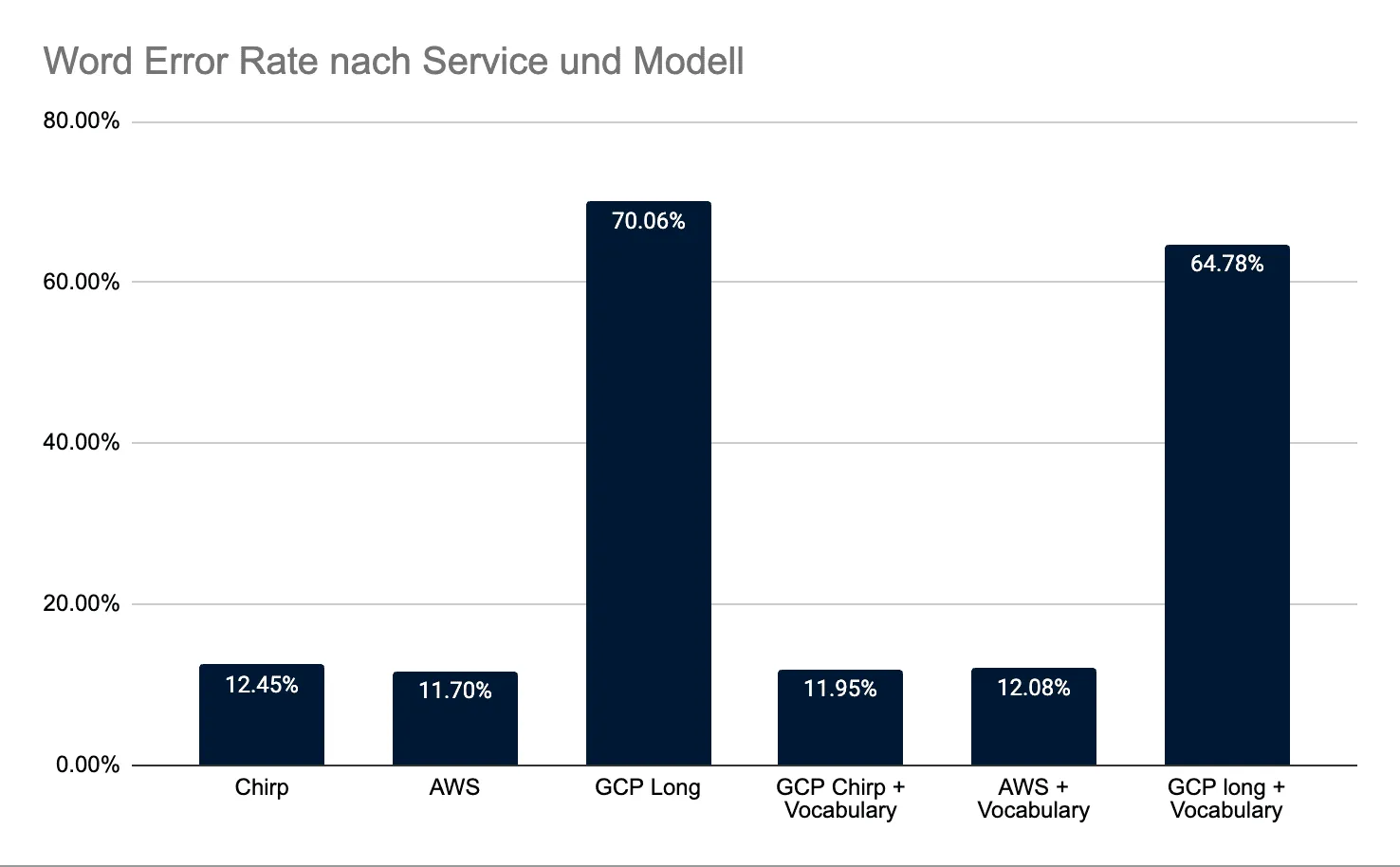
- Für deutschsprachige Live‑Transkription mit strenger Latenzbegrenzung war AWS Transcribe am zuverlässigsten (WER 11,70%).
- GCP Chirp2 profitierte moderat von Phrase Sets (WER 12,45% → 11,95%).
- GCP Long lieferte im Streaming-Setup wegen hoher/inkonsistenter Latenz massive Deletionen (WER 64–70%) und ist für Live ungeeignet.
Warum dich das interessieren sollte
Wenn du in Webinaren, Live‑Events oder Support‑Calls auf Echtzeit-Untertitel setzt, zählt nicht nur die Genauigkeit, sondern auch die Zuverlässigkeit im Zeitfenster. Diese Fallstudie zeigt, welche Dienste im Live‑Betrieb performen und wie du mit Phrase Sets/Vokabular nachhelfen kannst.
Setup in Kürze
- Sprache: Deutsch
- Input: ca. 6:30 Minuten kontinuierlicher Vortrag (Fachjargon, Zahlen, Eigennamen, Dialekte, Anglizismen)
- Dienste:
- AWS Transcribe
- GCP Cloud Speech-to-Text: Chirp2
- GCP Cloud Speech-to-Text: Long
- Jeweils mit und ohne Vokabular/Phrase Set (6 Durchläufe)
- Live-Streaming-Szenario: max. 40 Sekunden Latenz; spätere Ergebnisse wurden verworfen
- WER-Berechnung: (Substitutionen + Deletionen + Insertionen) / Gesamtwörter; Interpunktion normalisiert
Wichtige Randbedingung Ergebnisse, die später als 40 Sekunden eintrafen, galten als „verworfen“. Das benachteiligt Modelle mit langsamem/unkonstantem Finalisierungsverhalten – genau das trat beim GCP‑Long‑Modell auf.
Das Testtranskript (Anforderungen)
Der Vortrag „Die Zukunft der KI und ihre gesellschaftlichen Auswirkungen“ deckt gezielt Stolpersteine ab:
- Komposita (z. B. Donaudampfschifffahrtsgesellschaftskapitän)
- Zahlen/Statistiken (Geldbeträge, Prozent, Jahreszahlen, Telefonnummern, PLZ)
- Fachterminologie (Medizin, Physik, Biochemie, IT)
- Abkürzungen/Akronyme (NATO, UNESCO, BIP, DAX, EZB, ROI, DNA, RNA, IoT)
- Eigennamen/Institutionen (z. B. UKE, Volkswagen AG)
- Dialektale Ausdrücke (Schwäbisch, Bayerisch, Norddeutsch)
- Zeit-/Datumsangaben und Kontaktdaten
Das Ziel war, ein realistisches, „hartes“ Live‑Szenario zu simulieren.
Ergebnisse
| System | Word Error Rate | Accuracy | Errors | Correct | Subs | Del | Ins |
|---|---|---|---|---|---|---|---|
| Chirp | 12.45 % | 87.55% | 99 | 717 | 59 | 19 | 21 |
| Chirp + vocabulary | 11.95 % | 88.05% | 95 | 715 | 54 | 26 | 15 |
| AWS | 11.70 % | 88.30% | 93 | 712 | 70 | 13 | 10 |
| AWS + vocabulary | 12.08 % | 87.92% | 96 | 711 | 71 | 13 | 12 |
| GCP Long | 70.06 % | 29.94% | 557 | 250 | 48 | 497 | 12 |
| GCP long + vocabulary | 64.78 % | 35.22% | 515 | 303 | 55 | 437 | 23 |
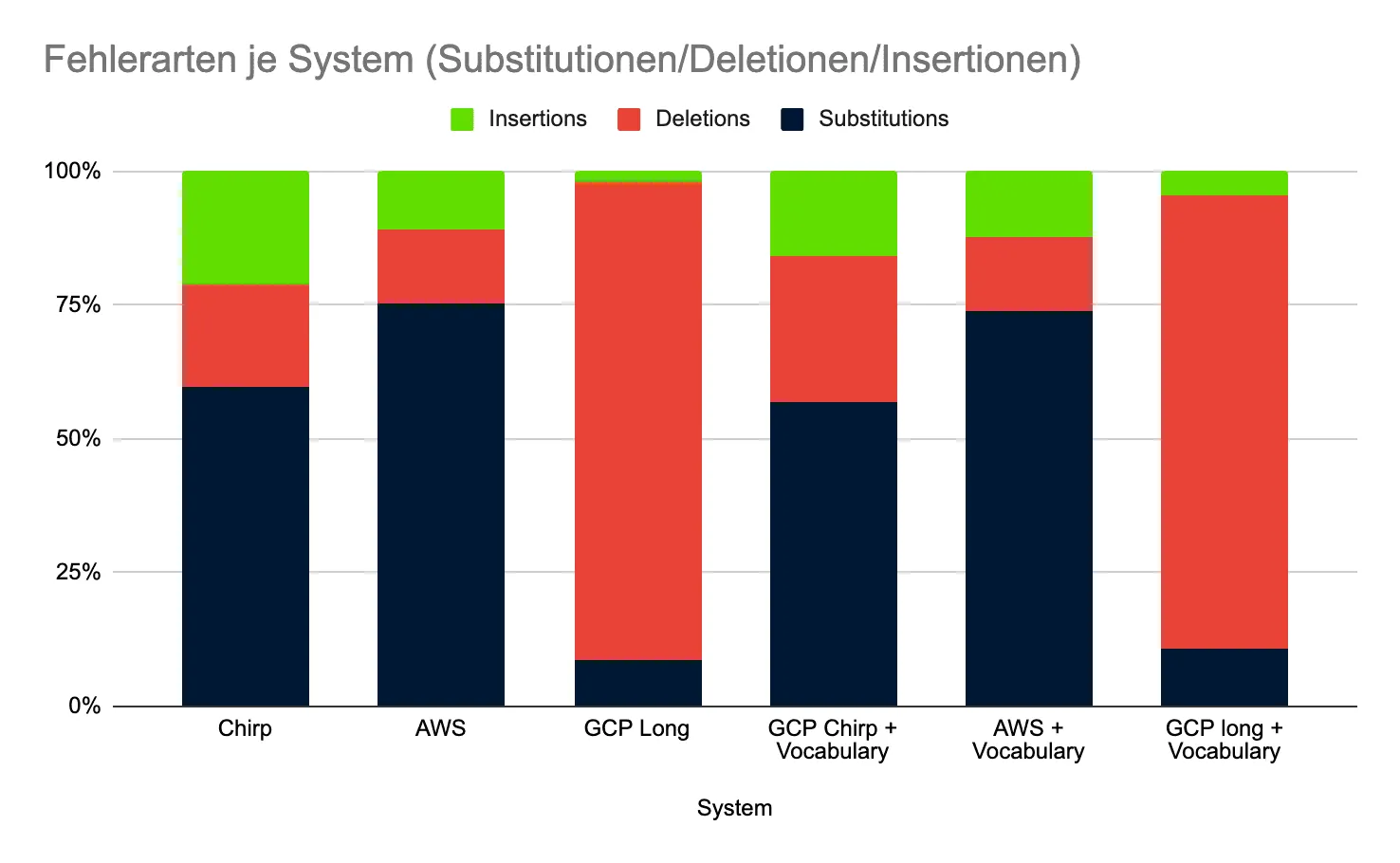
Subs: Ersetzte Wörter, Del: gelöschte Wörter, Ins: Eingefügte Wörter
Interpretation
- AWS Transcribe: niedrigste WER (11,70%), zugleich wenig Deletionen → im Live-Fenster zuverlässig.
- GCP Chirp2: ähnlich gut, mit Phrase Set eine leichte Verbesserung. Etwas mehr Deletionen als AWS, aber weniger Insertions/teils weniger Substitutionen.
- GCP Long: sehr hohe Deletionen (497 bzw. 437) → stark darauf hindeutend, dass Finalisierungen oft nicht im 40‑Sekunden‑Fenster ankamen. Mit Phrase Set minimal besser, aber weiterhin live problematisch.
Latency matters Die Latenz war bei GCP teils stark schwankend; AWS lief stabiler. Ohne konsistente Finalisierungen klettert die WER – nicht, weil die akustische Modellierung per se „schlecht“ ist, sondern weil Ergebnisse schlicht zu spät kommen.
Was bedeuten Phrase Sets/Vokabular in der Praxis?
- GCP Chirp2 profitierte leicht von Phrase Sets (−0,5 Prozentpunkte WER), v. a. bei Eigennamen/Terminologie.
- AWS zeigte mit Phrase Set hier keinen Vorteil (sogar minimal schlechter). Ursache kann ein Over‑Biasing sein, das zu Substitutionen/Insertionen führt.
- GCP Long profitiert inhaltlich etwas, bleibt aber im Live-Modus wegen Latenz problematisch.
Pragmatischer Tipp
- Nutze Phrase Sets selektiv und spezifisch (Eigennamen, Produktbegriffe, Akronyme).
- Teste Gewichtungen; zu aggressive Boosts können Fehlzuordnungen erhöhen.
- Aktualisiere Phrase Sets dynamisch vor Events (z. B. Speaker‑Namen, Agenda, Firmennamen).
Empfehlungen für deinen Live‑Setup
- Wähle das Modell nach Modus, nicht nur nach „Genauigkeit auf dem Papier“
- Live (strenge Latenz): AWS Transcribe oder GCP Chirp2 (mit vorsichtigem Phrase Set) sind praktikabel.
- Offline/Batch: GCP Long kann interessant sein – aber nicht für enge Echtzeitfenster.
- Plane für Latenz-Unsicherheiten
- Setze Timeouts, aber logge Späterückläufer separat für Post‑Event‑Auswertungen.
- Verwende Puffer/Segmentierung (z. B. 10–15‑Sekunden‑Chunks), um stabilere Finalisierungen zu fördern.
- Optimiere Akustik und Normalisierung
- Saubere, konstante Audiopegel; vermeide Raumhall.
- Post‑Processing: Zahlen/Datums-/Telefonformatierung mit RegEx/Heuristiken korrigieren.
- Spracherkennung mit Domain-Wissen ergänzen (z. B. Abkürzungen-Mapper).
- Messe nicht nur WER
- Trenne Fehlerarten: Hohe Deletion → Latenz-/Stabilitätsproblem, hohe Substitution → Akustik/Sprachmodell oder Over‑Biasing, hohe Insertion → zu aggressive Hypothesen.
- Beobachte „Time‑to‑Final“ und Revisionshäufigkeit von Zwischenhypothesen.
Grenzen der Studie
- Ein einziger Vortrag, wenn auch inhaltlich breit und anspruchsvoll.
- Sechs nacheinander statt parallel; mögliche Lauf‑zu‑Lauf‑Varianz.
- Keine quantitativen Latenz‑Metriken erhoben (nur qualitative Beobachtung).
- Vendor‑Konfigurationen nicht bis ins Maximum getuned (bewusst praxisnah).
So holst du mehr aus eigenen Tests
- Nutze mehrere Sprecher, Umgebungen und Längen.
- Logge Time‑to‑Final, Stabilität von Zwischenhypothesen, Jitter.
- Teste verschiedene Phrase‑Set‑Gewichtungen und Kanal-/Sample‑Rates.
Fazit
Für deutschsprachige Live‑Transkription mit engem Latenzfenster war in diesem Test AWS Transcribe die robusteste Wahl, knapp gefolgt von GCP Chirp2 (mit leichtem Boost durch Phrase Sets). Das GCP‑Long‑Modell lieferte im Streaming‑Betrieb zu viele Deletionen, vermutlich wegen verspäteter Finalisierungen.
Wenn du heute ein Live‑Event betexten willst, beginne mit AWS oder GCP Chirp2, halte Phrase Sets schlank und messbar, und überwache konsequent Latenz und Fehlerarten. So bekommst du verlässlichere Untertitel – und ein besseres Erlebnis für dein Publikum.


